Parse
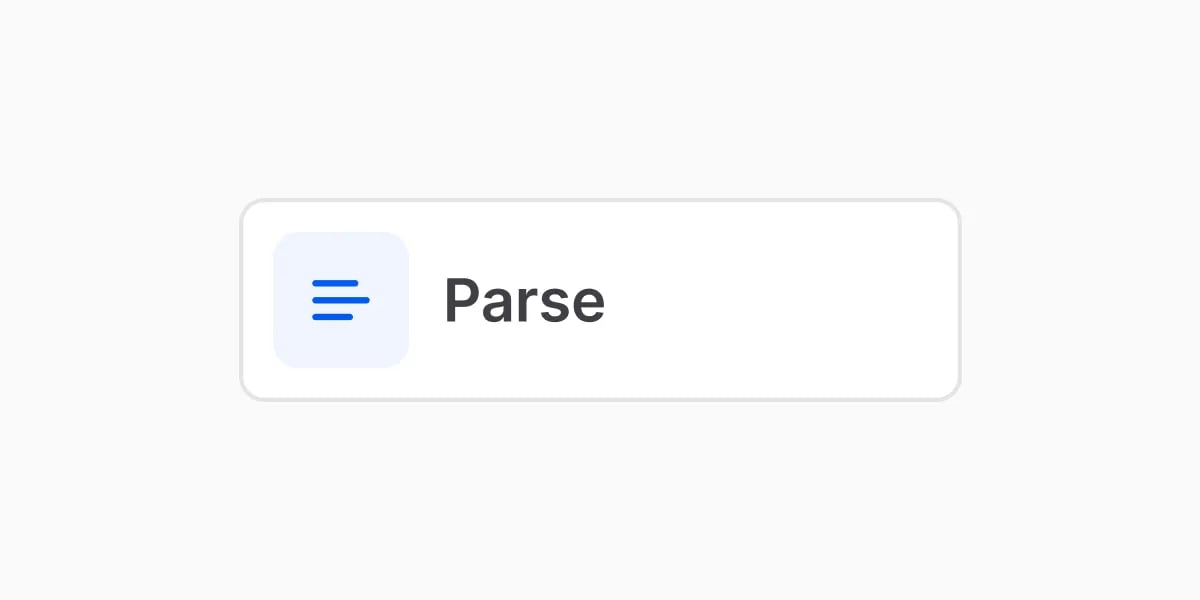
- You configure: usually nothing — Parse works out of the box. Advanced options let you give a hint about the document or tune how figures are handled.
- Add it when: always. It’s the first step in every workflow.
Example: upload a bank statement PDF — Parse reads and prepares all the text and layout.
Extract
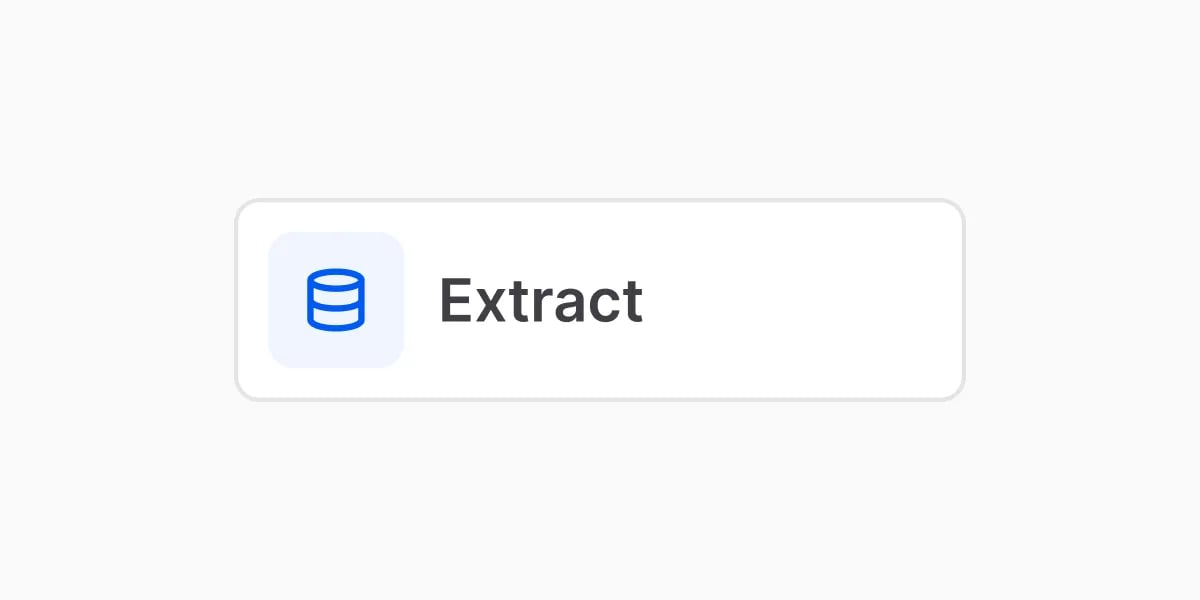
- You configure: the list of fields — each with a name, a type, and an instruction. This is your schema.
- Add it when: you want specific values back (the usual case). Skip it only for a parse-only workflow.
Example: define fields like “Account number”, “Transaction date”, and “Amount” to get them from every statement.
Classify
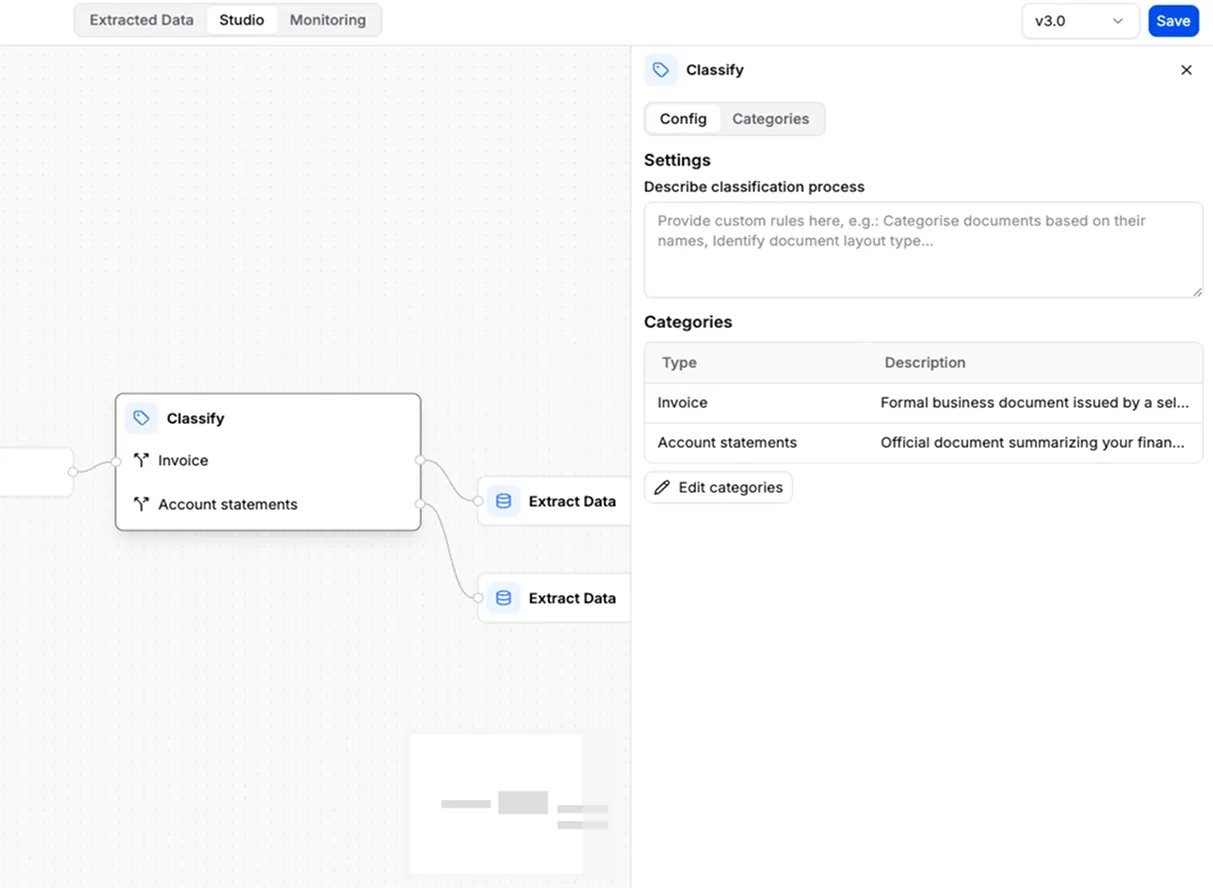
- You configure: a list of categories, each with a name and a short description of what belongs in it.
- Add it when: one workflow needs to handle several kinds of document — for example a mailbox that receives both invoices and contracts. After Classify, connect a separate Extract step for each category.
Example: automatically label incoming files as “Invoice”, “Contract”, or “Statement”.
Split
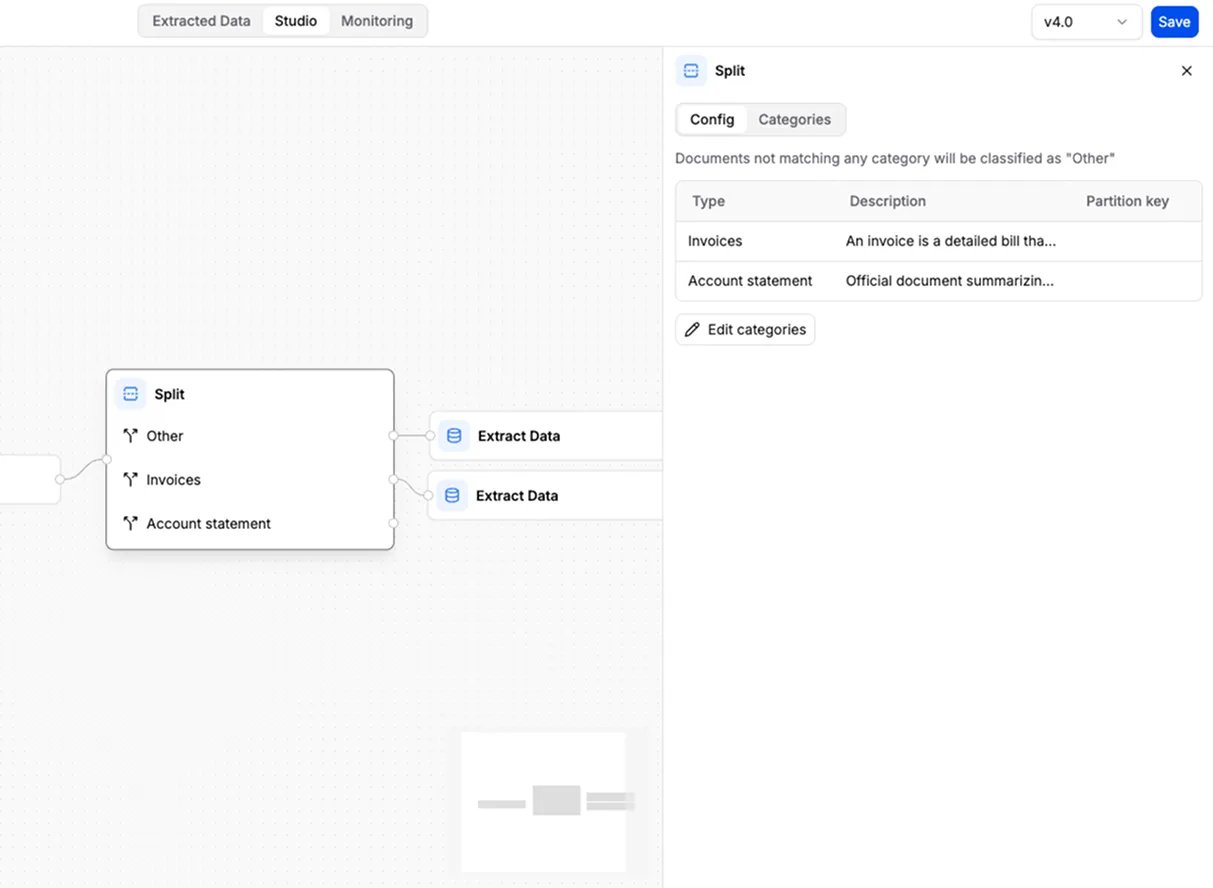
- You configure: the split rules, each with a name and a description. Anything that doesn’t match a rule is grouped as “other”.
- Add it when: your uploads bundle several documents together — for example a single PDF with four invoices, or a 50-page report you want handled page by page.
Example: a 50-page report gets split so each section is processed separately.
Validate (Beta)
Validate vs. verify — two different things. The Validate step is an automatic check built into the workflow: anyformat runs your rules on every document. Verifying is something you do by hand afterward — marking a value as correct with the thumbs-up (see Verification & review). One is the machine checking your rules; the other is you confirming the result.
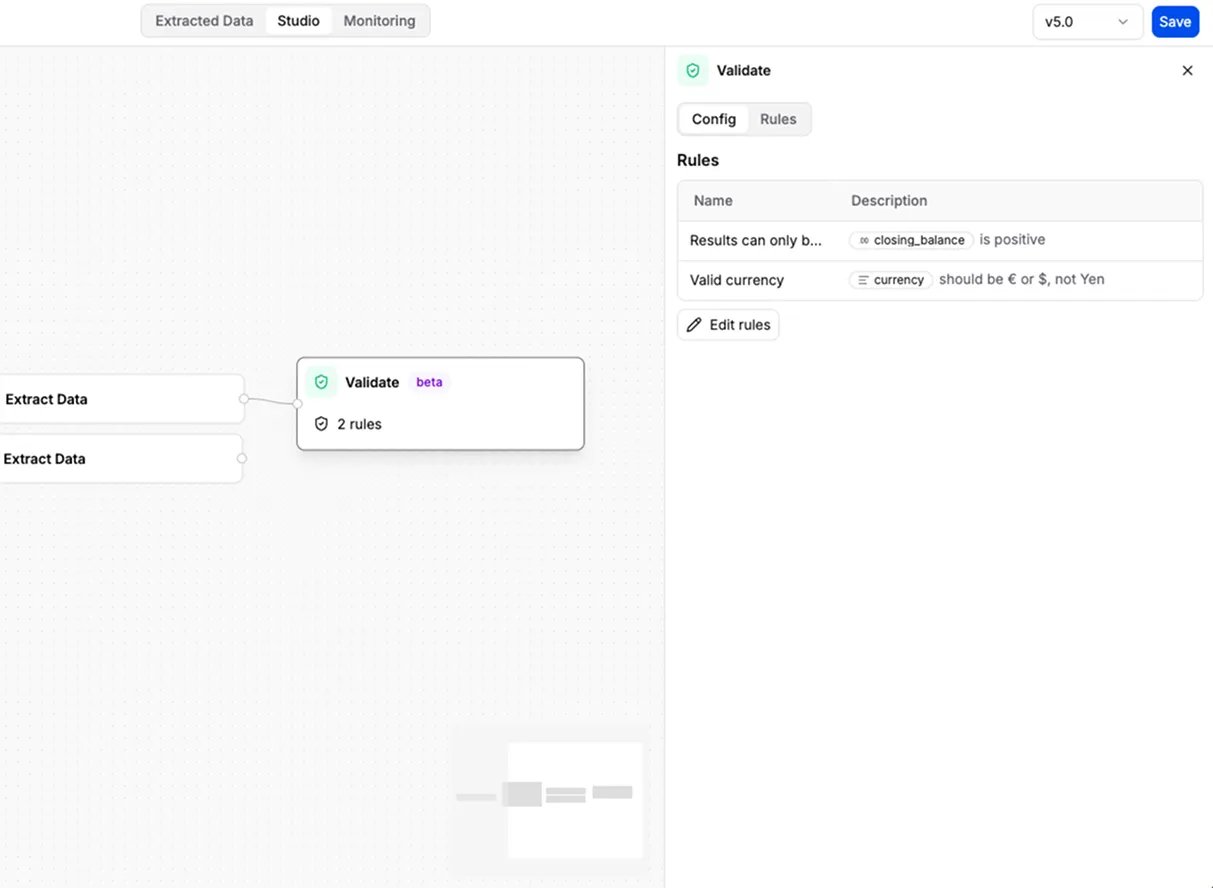
- You configure: a list of rules, each with a name and a plain-language description (for example, “the IBAN is a valid format” or “the document is not expired”).
- Add it when: some results must meet conditions you can state in words, and you want failures flagged automatically. Place Validate after the Extract step whose output you want to check.
- Where results show up: failures appear in the Validation tab of the results, alongside the extracted data.
Example: check that the name on an ID matches the name on the contract, verify an IBAN’s format, or flag expired documents.
What’s next?
Using Studio
Open Studio, add steps, and connect them
Field types
The kinds of values an Extract step can return