Once you’ve validated documents, anyformat helps you measure how well your workflows are performing. The Analytics tab in each workflow gives you visibility into:Documentation Index
Fetch the complete documentation index at: https://docs.anyformat.ai/llms.txt
Use this file to discover all available pages before exploring further.
- How reliable processing is
- Where errors tend to appear
- Which fields need attention
Confidence
What is confidence?
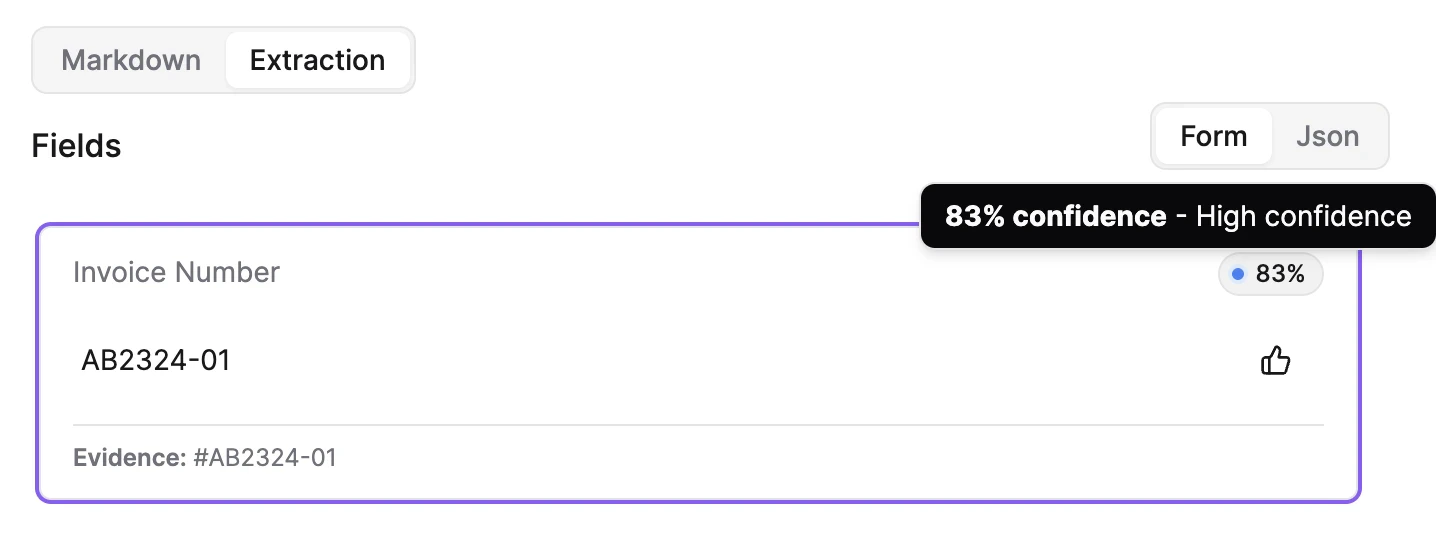
Confidence represents how certain anyformat is about an extracted value. It’s expressed as a percentage:- High confidence - the model is very sure
- Low confidence - the value may be ambiguous or unclear
- Field
- Document
- Workflow (average)
What confidence is (and isn’t)
Confidence IS
- A signal, not a verdict
- A way to prioritize human review
- A guide for where to look first
Confidence is NOT
- A guarantee of correctness
- A replacement for validation
- A measure of business accuracy
- High confidence and still be wrong
- Low confidence and still be correct
How to use confidence effectively
Use confidence to:- Focus review on low-confidence fields
- Skip reviewing obviously reliable values
- Reduce overall human effort
Accuracy explained
What is accuracy?
Accuracy measures how often extracted values are correct, based on human validation.Accuracy reflects validated correctness, not model certainty.Accuracy is calculated from:
- Fields validated as correct
- Fields corrected by humans
Accuracy vs confidence
| Confidence | Accuracy |
|---|---|
| Model certainty | Human-confirmed correctness |
| Available immediately | Improves over time |
| Predictive | Retrospective |
| Helps prioritize review | Measures real performance |
- Confidence to guide review
- Accuracy to judge quality
What accuracy tells you
Accuracy helps you answer:- Can I trust this workflow?
- Is it ready to scale?
- Which fields are fragile?
- Ambiguous instructions
- Poor field definitions
- Edge cases in documents
Viewing analytics
Workflow-level analytics
In the Analytics tab of a workflow, you can see:- Average confidence
- Average accuracy
- Trends over time (if available)
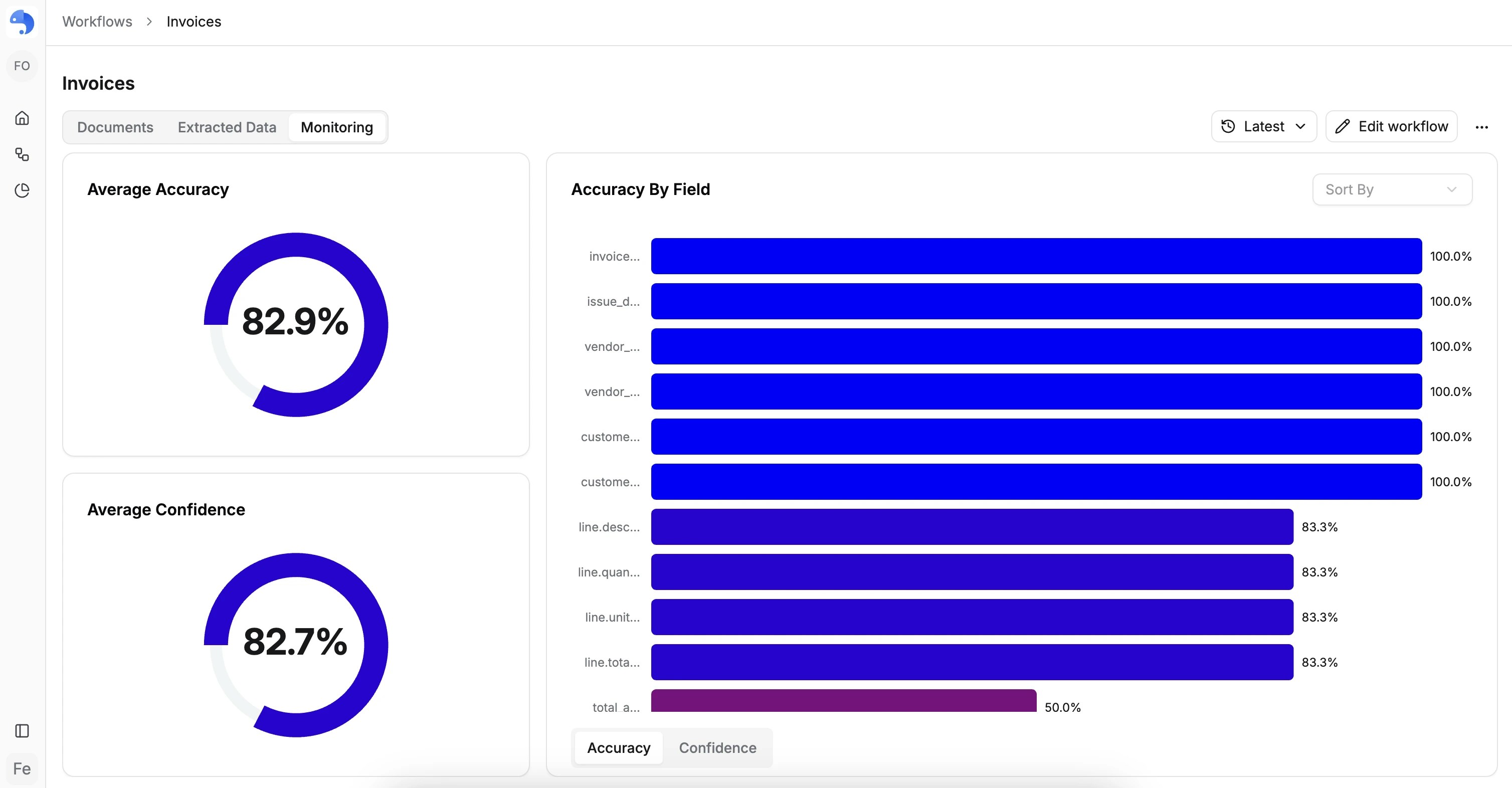
Field-level analytics
You can also analyze metrics per field:- Average confidence by field
- Accuracy by field
- Sort fields by performance
- Fields that consistently fail
- Fields that don’t need review anymore
- Outliers dragging accuracy down
Improving results
How to improve confidence
To improve confidence:- Make instructions more explicit
- Clarify where information appears
- Reduce ambiguity in field definitions
- Split complex fields into simpler ones
How to improve accuracy
To improve accuracy:- Correct wrong values during validation
- Review low-confidence fields carefully
- Refine the workflow when patterns appear
- Adjust schemas or instructions if needed
When to refine the workflow
You should consider refining a workflow when:- The same field is often corrected
- Accuracy plateaus below expectations
- New document variations appear
Refinement improves future documents, not past ones.
A realistic quality goal
You don’t need:- 100% confidence
- 100% accuracy
High accuracy with focused human review on low-confidence cases.That’s how anyformat scales without burning time.
How Analytics fits into the bigger picture
Validation tells you what is correct now. Analytics tells you how good the system is overall. Together, they help you:- Decide where to spend time
- Decide when to scale
- Decide when a workflow is “good enough”
What’s next?
Data & Structure
Improve field definitions and instructions
API Reference
Automate workflows programmatically